生产环境最佳实践:性能和可靠性
本文讨论了部署到生产环境的 Express 应用程序的性能和可靠性最佳实践。
This topic clearly falls into the “devops” world, spanning both traditional development and operations. Accordingly, the information is divided into two parts:
- 代码中的注意事项(开发部分)。
- 通过 Gzip 压缩,有助于显著降低响应主体的大小,从而提高 Web 应用程序的速度。可使用压缩中间件进行 Express 应用程序中的 gzip 压缩。例如:
- 不使用同步函数
- 正确进行日志记录
- Handle exceptions properly
- Things to do in your environment / setup (the ops part):
- 将 NODE_ENV 设置为“production”
- Node 应用程序在遇到未捕获的异常时会崩溃。您需要确保应用程序经过彻底测试,能够处理所有异常,这一点最为重要(请参阅正确处理异常以了解详细信息)。但是,作为一种防故障措施,请实施一种机制,确保应用程序崩溃后可以自动重新启动。
- 在集群应用程序中,个别工作进程的崩溃并不会影响其余的进程。除了性能优势,故障隔离是运行应用程序进程集群的另一原因。每当工作进程崩溃时,请确保始终使用 cluster.fork() 来记录事件并生成新进程。
- 高速缓存请求结果
- 使用负载均衡器
- 逆向代理位于 Web 应用程序之前,除了将请求转发给应用程序外,还对请求执行支持性操作。它还可以处理错误页、压缩、高速缓存、文件服务和负载均衡等功能。
Things to do in your code
以下是为改进应用程序性能而在代码中要注意的事项:
- 通过 Gzip 压缩,有助于显著降低响应主体的大小,从而提高 Web 应用程序的速度。可使用压缩中间件进行 Express 应用程序中的 gzip 压缩。例如:
- 不使用同步函数
- 正确进行日志记录
- Handle exceptions properly
使用 gzip 压缩
Gzip compressing can greatly decrease the size of the response body and hence increase the speed of a web app. Use the compression middleware for gzip compression in your Express app. For example:
const compression = require('compression')
const express = require('express')
const app = express()
app.use(compression())
For a high-traffic website in production, the best way to put compression in place is to implement it at a reverse proxy level (see Use a reverse proxy). In that case, you do not need to use compression middleware. 对于生产环境中的大流量网站,实施压缩的最佳位置是在反向代理层级(请参阅使用反向代理)。在此情况下,不需要使用压缩中间件。有关在 Nginx 中启用 gzip 压缩的详细信息,请参阅 Nginx 文档中的 ngx_http_gzip_module 模块。
不使用同步函数
Synchronous functions and methods tie up the executing process until they return. A single call to a synchronous function might return in a few microseconds or milliseconds, however in high-traffic websites, these calls add up and reduce the performance of the app. Avoid their use in production.
虽然 Node 和许多模块提供函数的同步和异步版本,但是在生产环境中请始终使用异步版本。只有在初始启动时才适合使用同步函数。 The only time when a synchronous function can be justified is upon initial startup.
You can use the --trace-sync-io command-line flag to print a warning and a stack trace whenever your application uses a synchronous API. Of course, you wouldn’t want to use this in production, but rather to ensure that your code is ready for production. See the node command-line options documentation for more information.
正确处理异常
In general, there are two reasons for logging from your app: For debugging and for logging app activity (essentially, everything else). Using console.log() or console.error() to print log messages to the terminal is common practice in development. But these functions are synchronous when the destination is a terminal or a file, so they are not suitable for production, unless you pipe the output to another program.
For debugging
如果您出于调试目的进行日志记录,请使用 debug 这样的特殊调试模块,而不要使用 console.log()。此模块支持您使用 DEBUG 环境变量来控制将哪些调试消息(如果有)发送到 console.err()。为了确保应用程序完全采用异步方式,仍需要将 console.err() 通过管道传到另一个程序。但您并不会真的希望在生产环境中进行调试,对吧? This module enables you to use the DEBUG environment variable to control what debug messages are sent to console.error(), if any. To keep your app purely asynchronous, you’d still want to pipe console.error() to another program. But then, you’re not really going to debug in production, are you?
出于应用程序活动目的
If you’re logging app activity (for example, tracking traffic or API calls), instead of using console.log(), use a logging library like Pino, which is the fastest and most efficient option available.
正确处理异常
Node 应用程序在遇到未捕获的异常时会崩溃。不处理异常并采取相应的措施会导致 Express 应用程序崩溃并脱机。如果您按照以下确保应用程序自动重新启动中的建议执行,那么应用程序可以从崩溃中恢复。幸运的是,Express 应用程序的启动时间一般很短。然而,应当首先立足于避免崩溃,为此,需要正确处理异常。 Not handling exceptions and taking appropriate actions will make your Express app crash and go offline. If you follow the advice in Ensure your app automatically restarts below, then your app will recover from a crash. Fortunately, Express apps typically have a short startup time. Nevertheless, you want to avoid crashing in the first place, and to do that, you need to handle exceptions properly.
要确保处理所有异常,请使用以下方法:
在深入了解这些主题之前,应该对 Node/Express 错误处理有基本的了解:使用 error-first 回调并在中间件中传播错误。Node 将“error-first 回调”约定用于从异步函数返回错误,回调函数的第一个参数是错误对象,后续参数中包含结果数据。为了表明没有错误,可将 null 值作为第一个参数传递。回调函数必须相应地遵循“error-first”回调约定,以便有意义地处理错误。在 Express 中,最佳做法是使用 next() 函数,通过中间件链来传播错误。 Node uses an “error-first callback” convention for returning errors from asynchronous functions, where the first parameter to the callback function is the error object, followed by result data in succeeding parameters. To indicate no error, pass null as the first parameter. The callback function must correspondingly follow the error-first callback convention to meaningfully handle the error. And in Express, the best practice is to use the next() function to propagate errors through the middleware chain.
有关错误处理基本知识的更多信息,请参阅:
使用 try-catch
Try-catch 是一种 JavaScript 语言构造,可用于捕获同步代码中的异常。例如,使用 try-catch 来处理 JSON 解析错误(如下所示)。 Use try-catch, for example, to handle JSON parsing errors as shown below.
Here is an example of using try-catch to handle a potential process-crashing exception. This middleware function accepts a query field parameter named “params” that is a JSON object.
app.get('/search', (req, res) => {
// Simulating async operation
setImmediate(() => {
const jsonStr = req.query.params
try {
const jsonObj = JSON.parse(jsonStr)
res.send('Success')
} catch (e) {
res.status(400).send('Invalid JSON string')
}
})
})
However, try-catch works only for synchronous code. 然而,try-catch 仅适用于同步代码。而由于 Node 平台主要采用异步方式(尤其在生产环境中),因此 try-catch 不会捕获大量异常。
使用 promise
When an error is thrown in an async function or a rejected promise is awaited inside an async function, those errors will be passed to the error handler as if calling next(err)
app.get('/', async (req, res, next) => {
const data = await userData() // If this promise fails, it will automatically call `next(err)` to handle the error.
res.send(data)
})
app.use((err, req, res, next) => {
res.status(err.status ?? 500).send({ error: err.message })
})
Also, you can use asynchronous functions for your middleware, and the router will handle errors if the promise fails, for example:
app.use(async (req, res, next) => {
req.locals.user = await getUser(req)
next() // This will be called if the promise does not throw an error.
})
Best practice is to handle errors as close to the site as possible. So while this is now handled in the router, it’s best to catch the error in the middleware and handle it without relying on separate error-handling middleware.
What not to do
_请勿_侦听 uncaughtException 事件,当异常像气泡一样在事件循环中一路回溯时,就会发出该事件。为 uncaughtException 添加事件侦听器将改变进程遇到异常时的缺省行为;进程将继续运行而不理会异常。这貌似是防止应用程序崩溃的好方法,但是在遇到未捕获的异常之后仍继续运行应用程序是一种危险的做法,不建议这么做,因为进程状态可能会变得不可靠和不可预测。 Adding an event listener for uncaughtException will change the default behavior of the process that is encountering an exception; the process will continue to run despite the exception. This might sound like a good way of preventing your app from crashing, but continuing to run the app after an uncaught exception is a dangerous practice and is not recommended, because the state of the process becomes unreliable and unpredictable.
此外,uncaughtException 被公认为比较粗糙,建议从内核中将其移除。所以侦听 uncaughtException 并不是个好主意。这就是为何我们推荐诸如多个进程和虚拟机管理器之类的方案:崩溃后重新启动通常是从错误中恢复的最可靠方法。 So listening for uncaughtException is just a bad idea. This is why we recommend things like multiple processes and supervisors: crashing and restarting is often the most reliable way to recover from an error.
我们也不建议使用域。它一般并不能解决问题,是一种不推荐使用的模块。 It generally doesn’t solve the problem and is a deprecated module.
Things to do in your environment / setup
{#in-environment}
以下是为改进应用程序性能而在系统环境中要注意的事项:
- 将 NODE_ENV 设置为“production”
- Node 应用程序在遇到未捕获的异常时会崩溃。您需要确保应用程序经过彻底测试,能够处理所有异常,这一点最为重要(请参阅正确处理异常以了解详细信息)。但是,作为一种防故障措施,请实施一种机制,确保应用程序崩溃后可以自动重新启动。
- 在集群应用程序中,个别工作进程的崩溃并不会影响其余的进程。除了性能优势,故障隔离是运行应用程序进程集群的另一原因。每当工作进程崩溃时,请确保始终使用 cluster.fork() 来记录事件并生成新进程。
- 高速缓存请求结果
- 使用负载均衡器
- 逆向代理位于 Web 应用程序之前,除了将请求转发给应用程序外,还对请求执行支持性操作。它还可以处理错误页、压缩、高速缓存、文件服务和负载均衡等功能。
将 NODE_ENV 设置为“production”
The NODE_ENV environment variable specifies the environment in which an application is running (usually, development or production). One of the simplest things you can do to improve performance is to set NODE_ENV to production.
将 NODE_ENV 设置为“production”会使 Express:
- 高速缓存视图模板。
- 高速缓存从 CSS 扩展生成的 CSS 文件。
- 生成简短的错误消息。
Tests indicate that just doing this can improve app performance by a factor of three!
如果您需要编写特定于环境的代码,可以使用 process.env.NODE_ENV 来检查 NODE_ENV 的值。请注意,检查任何环境变量的值都会导致性能下降,所以应该三思而行。 Be aware that checking the value of any environment variable incurs a performance penalty, and so should be done sparingly.
在开发中,通常会在交互式 shell 中设置环境变量,例如,使用 export 或者 .bash_profile 文件。但是一般而言,您不应在生产服务器上执行此操作;而是应当使用操作系统的初始化系统(systemd 或 Upstart)。下一节提供如何使用初始化系统的常规详细信息,但是设置 NODE_ENV 对于性能非常重要(且易于操作),所以会在此重点介绍。 But in general, you shouldn’t do that on a production server; instead, use your OS’s init system (systemd). The next section provides more details about using your init system in general, but setting NODE_ENV is so important for performance (and easy to do), that it’s highlighted here.
对于 systemd,请使用单元文件中的 Environment 伪指令。例如: For example:
# /etc/systemd/system/myservice.service
Environment=NODE_ENV=production
For more information, see Using Environment Variables In systemd Units.
确保应用程序能够自动重新启动
In production, you don’t want your application to be offline, ever. This means you need to make sure it restarts both if the app crashes and if the server itself crashes. Although you hope that neither of those events occurs, realistically you must account for both eventualities by:
- 使用进程管理器在应用程序(和 Node)崩溃时将其重新启动。
- 在操作系统崩溃时,使用操作系统提供的初始化系统重新启动进程管理器。还可以在没有进程管理器的情况下使用初始化系统。 It’s also possible to use the init system without a process manager.
Node applications crash if they encounter an uncaught exception. The foremost thing you need to do is to ensure your app is well-tested and handles all exceptions (see handle exceptions properly for details). But as a fail-safe, put a mechanism in place to ensure that if and when your app crashes, it will automatically restart.
使用进程管理器
在开发中,只需在命令行从 node server.js 或类似项启动应用程序。但是在生产环境中执行此操作会导致灾难。如果应用程序崩溃,它会脱机,直到其重新启动为止。为了确保应用程序在崩溃后可以重新启动,请使用进程管理器。进程管理器是一种应用程序“容器”,用于促进部署,提供高可用性,并支持用户在运行时管理应用程序。 But doing this in production is a recipe for disaster. If the app crashes, it will be offline until you restart it. To ensure your app restarts if it crashes, use a process manager. A process manager is a “container” for applications that facilitates deployment, provides high availability, and enables you to manage the application at runtime.
除了在应用程序崩溃时将其重新启动外,进程管理器还可以执行以下操作:
- 获得对运行时性能和资源消耗的洞察。
- 动态修改设置以改善性能。
- Control clustering (pm2).
Historically, it was popular to use a Node.js process manager like PM2. See their documentation if you wish to do this. However, we recommend using your init system for process management.
使用初始化系统
下一层的可靠性是确保在服务器重新启动时应用程序可以重新启动。系统仍然可能由于各种原因而宕机。为了确保在服务器崩溃后应用程序可以重新启动,请使用内置于操作系统的初始化系统。目前主要使用两种初始化系统:systemd 和 Upstart。 Systems can still go down for a variety of reasons. To ensure that your app restarts if the server crashes, use the init system built into your OS. The main init system in use today is systemd.
有两种方法将初始化系统用于 Express 应用程序:
- 在进程管理器中运行应用程序,使用初始化系统将进程管理器安装为服务。进程管理器将在应用程序崩溃时将其重新启动,初始化系统则在操作系统重新启动时重新启动进程管理器。这是建议使用的方法。 The process manager will restart your app when the app crashes, and the init system will restart the process manager when the OS restarts. This is the recommended approach.
- Run your app (and Node) directly with the init system. This is somewhat simpler, but you don’t get the additional advantages of using a process manager.
Systemd
Systemd 是一个 Linux 系统和服务管理器。大多数主要 Linux 分发版采用 systemd 作为其缺省初始化系统。 Most major Linux distributions have adopted systemd as their default init system.
A systemd service configuration file is called a unit file, with a filename ending in .service. Here’s an example unit file to manage a Node app directly. Replace the values enclosed in <angle brackets> for your system and app:
[Unit]
Description=<Awesome Express App>
[Service]
Type=simple
ExecStart=/usr/local/bin/node </projects/myapp/index.js>
WorkingDirectory=</projects/myapp>
User=nobody
Group=nogroup
# Environment variables:
Environment=NODE_ENV=production
# Allow many incoming connections
LimitNOFILE=infinity
# Allow core dumps for debugging
LimitCORE=infinity
StandardInput=null
StandardOutput=syslog
StandardError=syslog
Restart=always
[Install]
WantedBy=multi-user.target
有关 systemd 的更多信息,请参阅 systemd 参考(联机帮助页)。
在集群中运行应用程序
在多核系统中,可以通过启动进程的集群,将 Node 应用程序的性能提升多倍。一个集群运行此应用程序的多个实例,理想情况下一个 CPU 核心上运行一个实例,从而在实例之间分担负载和任务。 A cluster runs multiple instances of the app, ideally one instance on each CPU core, thereby distributing the load and tasks among the instances.
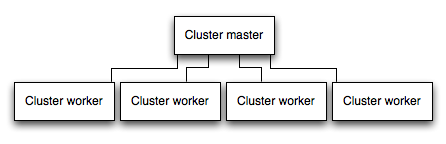
IMPORTANT: Since the app instances run as separate processes, they do not share the same memory space. That is, objects are local to each instance of the app. Therefore, you cannot maintain state in the application code. However, you can use an in-memory datastore like Redis to store session-related data and state. This caveat applies to essentially all forms of horizontal scaling, whether clustering with multiple processes or multiple physical servers.
In clustered apps, worker processes can crash individually without affecting the rest of the processes. Apart from performance advantages, failure isolation is another reason to run a cluster of app processes. Whenever a worker process crashes, always make sure to log the event and spawn a new process using cluster.fork().
使用 Node 的集群模块
Clustering is made possible with Node’s cluster module. This enables a master process to spawn worker processes and distribute incoming connections among the workers.
Using PM2
If you deploy your application with PM2, then you can take advantage of clustering without modifying your application code. You should ensure your application is stateless first, meaning no local data is stored in the process (such as sessions, websocket connections and the like).
When running an application with PM2, you can enable cluster mode to run it in a cluster with a number of instances of your choosing, such as the matching the number of available CPUs on the machine. You can manually change the number of processes in the cluster using the pm2 command line tool without stopping the app.
To enable cluster mode, start your application like so:
# Start 4 worker processes
$ pm2 start npm --name my-app -i 4 -- start
# Auto-detect number of available CPUs and start that many worker processes
$ pm2 start npm --name my-app -i max -- start
This can also be configured within a PM2 process file (ecosystem.config.js or similar) by setting exec_mode to cluster and instances to the number of workers to start.
Once running, the application can be scaled like so:
# Add 3 more workers
$ pm2 scale my-app +3
# Scale to a specific number of workers
$ pm2 scale my-app 2
For more information on clustering with PM2, see Cluster Mode in the PM2 documentation.
高速缓存请求结果
提高生产环境性能的另一种策略是对请求的结果进行高速缓存,以便应用程序不需要为满足同一请求而重复执行操作。
Use a caching server like Varnish or Nginx (see also Nginx Caching) to greatly improve the speed and performance of your app.
使用负载均衡器
无论应用程序如何优化,单个实例都只能处理有限的负载和流量。扩展应用程序的一种方法是运行此应用程序的多个实例,并通过负载均衡器分配流量。设置负载均衡器可以提高应用程序的性能和速度,并使可扩展性远超单个实例可以达到的水平。 One way to scale an app is to run multiple instances of it and distribute the traffic via a load balancer. Setting up a load balancer can improve your app’s performance and speed, and enable it to scale more than is possible with a single instance.
A load balancer is usually a reverse proxy that orchestrates traffic to and from multiple application instances and servers. You can easily set up a load balancer for your app by using Nginx or HAProxy.
对于负载均衡功能,可能必须确保与特定会话标识关联的请求连接到产生请求的进程。这称为_会话亲缘关系_或者_粘性会话_,可通过以上的建议来做到这一点:将 Redis 之类的数据存储器用于会话数据(取决于您的应用程序)。要了解相关讨论,请参阅 Using multiple nodes。 This is known as session affinity, or sticky sessions, and may be addressed by the suggestion above to use a data store such as Redis for session data (depending on your application). For a discussion, see Using multiple nodes.
使用逆向代理
A reverse proxy sits in front of a web app and performs supporting operations on the requests, apart from directing requests to the app. It can handle error pages, compression, caching, serving files, and load balancing among other things.
通过将无需了解应用程序状态的任务移交给逆向代理,可以使 Express 腾出资源来执行专门的应用程序任务。因此,建议在生产环境中,在 Nginx 或 HAProxy 之类的逆向代理背后运行 Express。 For this reason, it is recommended to run Express behind a reverse proxy like Nginx or HAProxy in production.
Edit this page